Lenovo reaffirmed its commitment to Hybrid AI for All during the company’s annual Global Industry Analyst Conference, held Oct. 20 to 23 at the company’s U.S. headquarters in Morrisville, N.C. The conference featured a series of closed-door sessions during which Lenovo executives briefed roughly 70 industry analysts on all things Lenovo, from liquid cooling to agentic AI solutions. Throughout the conference, Lenovo executives provided updates on the company’s overall strategy and ambitions to shift its perception from PC vendor to full-stack, end-to-end solution provider.
From PC vendor to full-stack solution provider
At its core, Lenovo is an engineering company with a particular strength in computing, having acquired IBM’s PC business and later its x86 server business. However, Lenovo’s investments in scope expansion underpin its transformation into a solutions- and services-led technology provider.
Since the formation of its Solutions and Services Group in 2020, Lenovo has not looked back. In 2024 the company announced its Hybrid AI Advantage framework, which serves as a powerful example of how the company’s portfolio is widening and how the company’s culture and go-to-market approach are evolving to emphasize its increasingly solutions- and services-led model and its growing focus on full-stack AI.
However, despite the company’s investments in transformation, Lenovo has retained its core competencies in engineering and manufacturing, leveraging its expertise and global footprint to drive innovation, cost efficiencies and scale. For example, in Lenovo Infrastructure Solutions Group, the company has leaned into its unique engineering and manufacturing capabilities to establish its rapidly growing ODM+ business, which targets cloud services providers.
Additionally, within the Lenovo Intelligent Device Group, the company has leveraged these capabilities to mitigate the impacts of tariffs and drive design innovation in an otherwise increasingly commoditized PC market. The company’s Solutions and Services business acts like a margin-enriching interconnective tissue over the company’s robust client and data center hardware portfolios and a catalyst to move the company further up the value chain.
As a dual-headquartered company (North Carolina and Beijing), Lenovo’s global footprint is unmatched by its hardware OEM peers, and the company’s business in China largely operates in its own silo. China is one of several regional launch markets for early pilots. However, Lenovo follows a local-first, global-by-design approach: Solutions are incubated to meet local data, content and regulatory requirements, and when there’s Rest of World (ROW) demand, Lenovo reimplements features for global compliance rather than porting code or models 1:1. No China-based user data, models or services are reused in ROW products.
Building on this global theme, during the conference Lenovo noted that it is hiring Lenovo AI Technology Center (LATC) engineers across the world, in places like Silicon Valley; Chicago; Raleigh, N.C.; Europe; Tel Aviv, Israel; and China. Additionally, the company highlighted its investment in establishing new AI centers of excellence to centralize and expand regional AI talent and support independent software vendors in their development of industry- and use-case-specific solutions. Rather than making a net-new investment, Lenovo has leveraged this strategy successfully to expand its AI library, a catalog of preconfigured AI solutions ready to be customized and deployed by Lenovo. In addition to industry- and use-case-specific AI solutions, the company also works with regional independent software vendors to develop solutions tailored to the preferences of customers in specific geographies, such as China.
While Lenovo’s portfolio and go-to-market strategy may differ slightly by geography, the company’s pocket-to-cloud and One Lenovo initiatives remain the same around the world and are the basis for the company’s differentiation in the market — a theme during every session of the conference. From smartphones to servers, Lenovo is vying for share in every segment, and by investing in the unification and openness of its portfolio, whether it be through the development of homegrown software or new ecosystem partnerships, the company is positioning to grow in the AI era. Changing its perception from a PC powerhouse to a solution provider remains one of Lenovo’s largest challenges, but the company’s work in sponsoring and supporting FIFA and F1 with its full-stack technology capabilities demonstrates its willingness to invest in overcoming this hurdle.
Lenovo is investing to win in enterprise AI and bring smarter AI to all
Lenovo’s AI strategy spans all three of the company’s business units and echoes the Smarter AI for All mantra and pocket-to-cloud value proposition.
During the conference Lenovo reemphasized its belief that the meaningful ramp-up of enterprise AI is on the horizon as AI inferencing workloads continue to proliferate. Lenovo has high-performance computing roots and its Infrastructure Solutions Group (ISG) derives a significant portion of its revenue from cloud service provider (CSP) customers, in contrast to some of its closest infrastructure OEM competitors, but Lenovo’s investments and the composition of the company’s portfolio emphasize the company’s intent on driving growth through its Enterprise and Small/Medium Business (ESMB) segment, supporting all levels of on-premises AI computing, from the core data center to the far edge.
Additionally, Lenovo continues to go against the grain on the notion that AI workloads belong exclusively on the GPU and makes a case for lighter workloads being deployed more efficiently on the CPU and in smaller edge server form factors. Lenovo’s view is heterogeneous AI: Training and high-throughput inference lean on GPUs; latency-sensitive and personal workloads increasingly run on NPUs and optimized CPUs, and the company’s portfolio spans all three — multi-GPU-ready workstations, edge servers with GPU/CPU mixes, and Copilot+ PCs with NPUs for local inference — so customers can place the right workload on the right engine.
However, perhaps what differentiates Lenovo’s infrastructure portfolio most is the company’s Neptune liquid cooling technology, which comes in three flavors: Neptune, Neptune Core and Neptune Air. Intensive AI and machine-learnings workloads require dense compute infrastructure that, in some cases, generates so much heat it requires liquid cooling as opposed to traditional air cooling. In addition, even less-intensive workloads often benefit from liquid cooling, which generally operates at lower costs once implemented. This is where Neptune liquid cooling comes in.
The company’s flagship Neptune solution offers full system liquid cooling, making it ideal for the most demanding AI and high-performance computing workloads. The company’s other two offerings — Neptune Core and Neptune Air — deliver lower levels of heat removal but are more easily implemented. For instance, while Neptune Air offers the lowest levels of heat removal, the simplicity of the solution makes it easier to implement, especially in existing data center environments, supporting lower cost transitions to liquid cooling.
TBR sees Lenovo’s family of Neptune solutions as a major advantage, as the variety of offerings targets customers and environments in different stages of liquid cooling adoption. Lenovo’s experience in retrofitting data centers with liquid cooling also presents a strong services opportunity for the company and supports enterprise adoption of higher-power AI servers in their on-premises environments. Further, because liquid cooling is more efficient than air cooling, Neptune supports Lenovo’s sustainability initiatives and delivers strong total cost of ownership savings in many scenarios, which is something IT decision makers tend to scrutinize heavily when making investments.
Unlike its close competitors that have invested heavily in data management and orchestration layers leveraging their networking and storage solutions, Lenovo does not play in the data center networking space, instead choosing to be networking-agnostic and partner-first in this area, which the company sees as an advantage due to geographical differences in customer preference. However, the company’s results have yet to prove that this networking strategy is materially advantageous. Additionally, while complex, networking is typically more margin rich than compute and storage while also presenting myriad attach and services opportunities for OEMs with first-party full-stack infrastructure portfolios.
Adjacent to the company infrastructure offerings, during the conference Lenovo executives stated that there should more adoption of workstations as part of enterprises’ on-premises AI adoption and solution development. Compared to sandboxing AI solutions in the cloud, Lenovo sees its workstations, which can support up to four NVIDIA RTX discrete GPUs, as a more practical and economical solution compared to cloud resources. However, in addition to the company’s Windows-based workstations, Lenovo also showed off its NVIDIA DGX Spark inspired desktop geared more heavily toward use in conjunction with NVIDIA DGX cloud.
Rather than running Windows OS, Lenovo’s DGX Spark inspired desktop runs DGX OS, a Linux-based operating system and is ideal for buyers that already have DGX cloud resources. With desktop offerings for AI spanning multiple operating systems, Lenovo’s Intelligent Device Group showcases the company’s ambition to create AI systems for all types of users. Looking ahead, both TBR and Lenovo expect the adoption of GPU-enabled workstations to grow as an increasing number of enterprises experiment with the development and/or customization of preconfigured AI solutions.
Through a services lens, Lenovo’s enterprise AI strategy centers on the company’s Hybrid AI Advantage framework. Similar to frameworks used by competitors such as Dell Technologies and HPE, Hybrid AI Advantage includes NVIDIA AI Enterprise software components intended to allow for the development of industry- and use-case-specific AI solutions. However, while NVIDIA AI Enterprise can be thought of as a collection of foundational tools to build AI agents, Lenovo’s AI library goes a set up further, offering more out-of-the-box types of industry- and use-case-specific AI solutions.
The composition of Lenovo AI library is largely predicated on solutions developed in conjunction with ISVs through Lenovo’s AI Innovators program. As Lenovo expands its footprint of AI centers of excellence, TBR expects the number of customizable, near-plug-and-play AI solutions to grow, further cementing the company’s differentiation in the marketplace. Additionally, Lenovo argues that its Agentic AI Platform further differentiates Hybrid AI Advantage from what is offered by competitors.
Lenovo’s Solutions and Services Group is equipped with strengthening auxiliary services to support customers wherever they are on their AI journey. This is where the company’s Hybrid AI framework comes into play. The framework has five components: AI discover, AI advisory, AI fast start, AI deploy and scale, and AI managed. The first two components underscore Lenovo’s growing emphasis on delivering professional services, while the third component — where many customers enter the framework — is where Lenovo aligns customers with a solution from the company’s AI library. The last two components highlight Lenovo’s ongoing interest in delivering deployment and ultimately managed services through the company’s maturing TruScale “as a Service” business that caters to both infrastructure solutions and devices deployments.
At the end of the day, Lenovo understands that hardware — specifically compute hardware like PCs and servers — is its strength, but by developing prebuilt solutions and overlaying its expanding services capabilities, the company is investing in moving up the value chain to drive margin expansion and deepen customer engagement.
Intelligent Device Group is doubling down on its unified ecosystem play
At 67.3% of total reported segment revenue in 2Q25, Lenovo’s Intelligent Device Group accounts for the lion’s share of the company’s top line, and TBR estimates 88.5% of the segment’s revenue is derived from the sale of PCs. Over the trailing 12-month (TTM) period ending in 2Q25, TBR estimates the company’s PC business generated nearly $40 billion, growing 14.6% year-to-year and resulting in an approximate 130-basis-point expansion in PC market share, according to TBR’s 2Q25 Devices Benchmark.
In line with the company’s ambitions to change its perception from a PC vendor to a solutions provider, and due to the company’s already established footprint in the PC market, much of the general sessions during the conference focused on the company’s AI position, with specific emphasis on Solutions and Services Group and Infrastructure Solutions Group. However, during the Intelligent Device Group briefings, Lenovo executives confirmed the company has no intention of giving up share in devices — the business on which the company’s success has been predicated. Lenovo touted its leadership position in several segments of the PC market, with the largest being the commercial space. Business leaders acknowledged that it is a good time to take share in the commercial Windows PC market, and by investing in the development of proprietary components and feature sets, the company is actively dispelling the notion that the PC market is fully commoditized. Lenovo has continued its engineering collaboration with Microsoft on CoPilot+ PCs.
Beyond the PC, Lenovo’s investments in growing the share of its Motorola smartphone business have been paying off, and the company is not taking its foot off the gas. To drive cross-selling opportunities, the company is deploying a marketing strategy targeting a younger customer base and is leaning into creating a unified device ecosystem integrated with AI features and capabilities, something the company refers to as its One AI, Multiple Devices strategy. However, unlike other unified device ecosystem plays, such as that of Apple, Lenovo’s play is more open, with the company supporting cross-device features between its PCs and smartphones running both Android OS and iOS. Thus far, Lenovo has seen limited traction in cross-selling smartphones and PCs in the commercial space; however, TBR believes the company’s One AI, Multiple Devices strategy could help shift the tide.
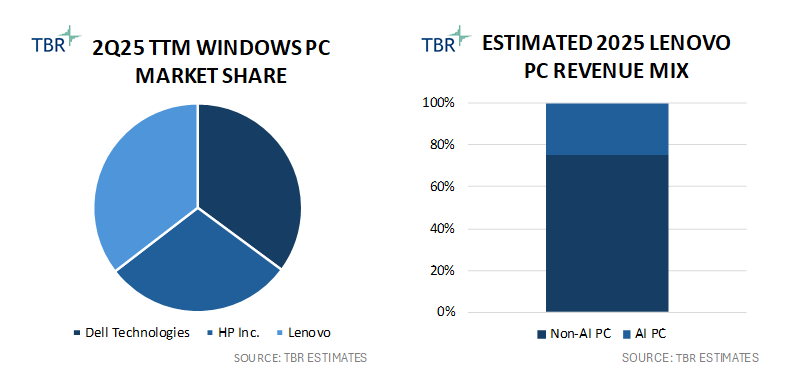
2Q25 TTM Windows PC Market Share and Estimated 2025 Lenovo PC Revenue Mix (Source: TBR)
During its Global Industry Analyst Conference, Lenovo’s focus on maintaining and even expanding its leadership position in the commercial PC segment was obvious, but what was perhaps more interesting was how the company is marketing several of its PCs that are in direct competition with Apple in an effort to appeal to a younger segment of the PC market. Lenovo is promoting its device brand as premium, trusted and innovative — aspects supported by the company’s leadership in PC design and engineering as well as its ongoing investments in device security through proprietary software developments. Lenovo also showcased innovative designs, such as motorized expanding screens, and developments down to the motherboard level, which harkened back to the company’s core legacy competencies in engineering and manufacturing.
Through partnerships and portfolio innovation, Lenovo is gradually changing its perception in the industry
Lenovo’s FIFA and F1 partnerships underscore the company’s investments in growing its brand recognition globally and changing its perception from PC vendor to solutions provider. For example, Lenovo infrastructure will power semi-automated offsides calls during the World Cup via computer vision technology. Additionally, Lenovo continues to leverage its Neptune liquid cooling technology as a key differentiator. During the conference Kate Swanborg, SVP, Technology Communications and Strategic Alliances, DreamWorks Animation, discussed how Neptune has allowed DreamWorks to consolidate its data center footprint from 210 air-cooled servers down to 72 liquid-cooled servers.
By leveraging its global engineering and manufacturing footprint in combination with its expanding ecosystem of ISV partners, Lenovo’s emphasis on hardware innovation and supply chain agility aligns with the company’s ever-growing AI library and its establishment of AI centers of excellence, to support Lenovo’s ambitions of driving enterprise AI adoption across all kinds of on-premises environments. Constant investments in IT operations management platforms and unified device ecosystem software demonstrate Lenovo’s focus on driving cross-selling within and across its hardware portfolios while increasing the value proposition behind the company’s TruScale managed service offerings.